ARCHIE
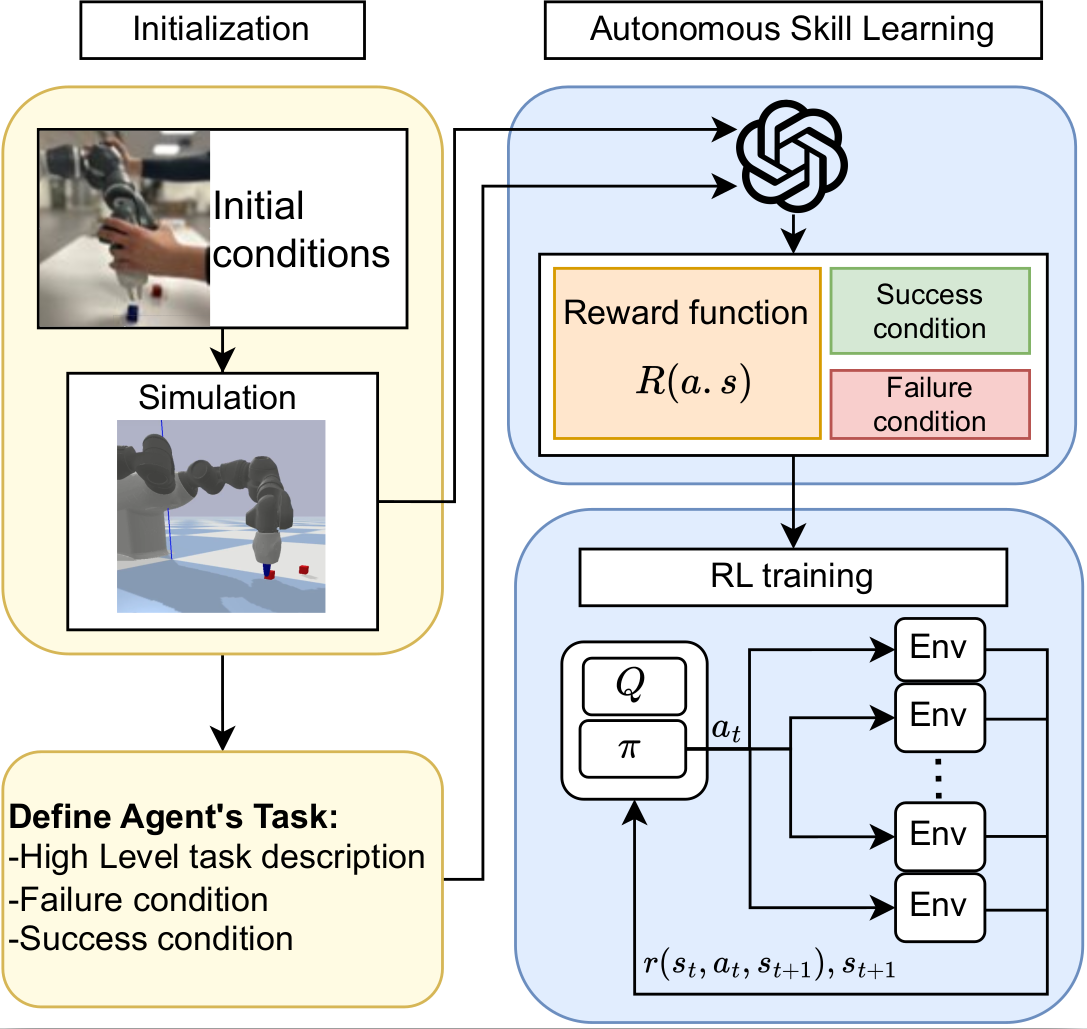
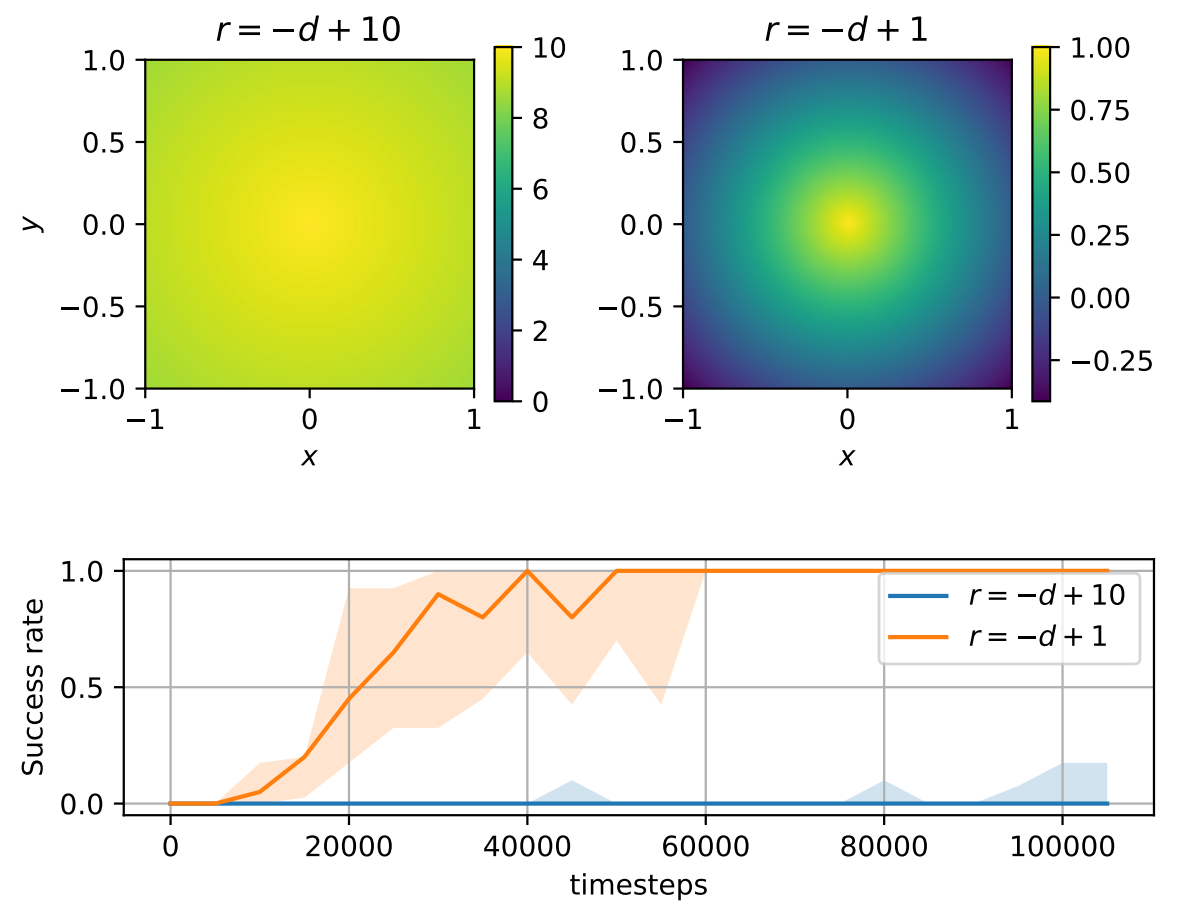
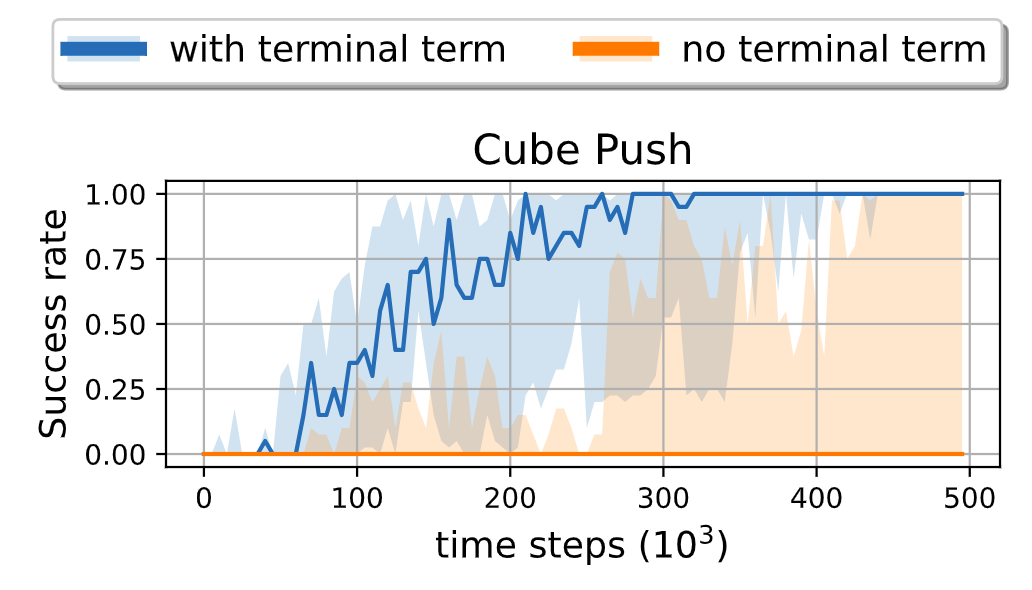
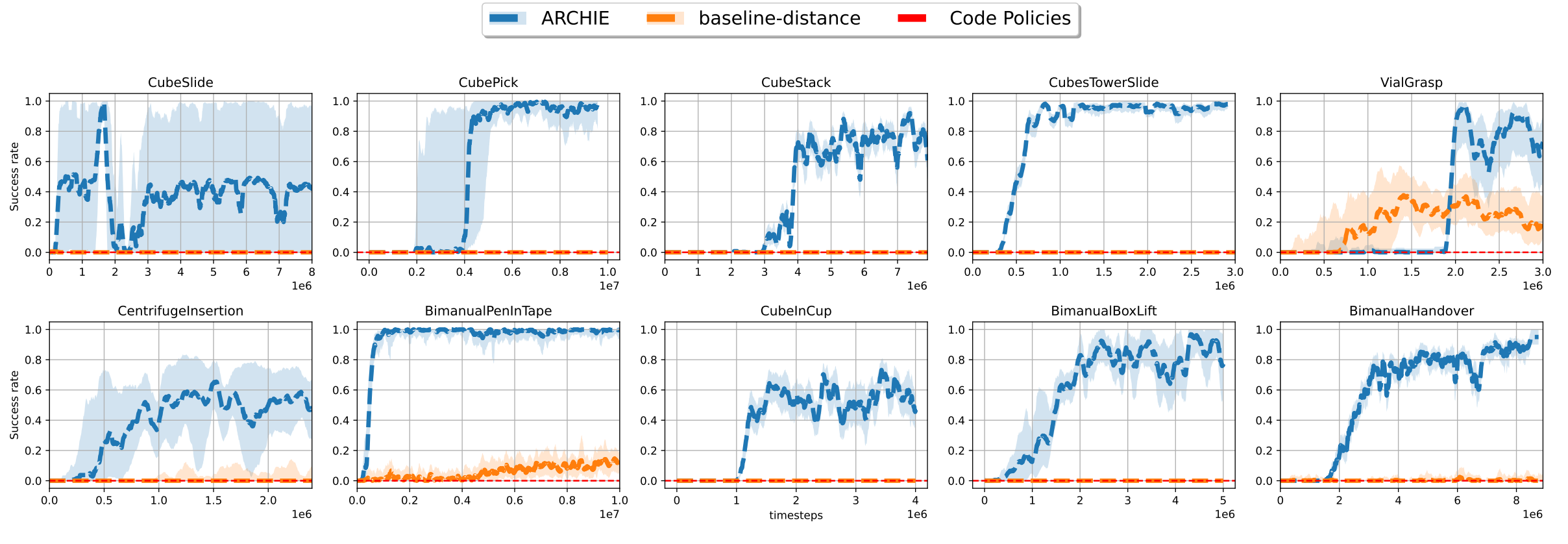
In this work, we propose Autonomous Reinforcement learning for Complex Human-Informed Environments (ARCHIE). ARCHIE is a practical automatic RL pipeline for training autonomous agents for robotics manipulation tasks, in an unsupervised manner. ARCHIE employs GPT-4 —a popular pretrained LLM— for reward generation from human prompts. We leverage natural language descriptions to generate reward functions via GPT-4, which are then used to train an RL agent in a simulated environment. Our approach introduces a formalization of the reward function that constrains the language model’s code generation, enhancing the feasibility of task learning at the first attempt. Unlike previous methods, we also utilize the language model to define the success criteria for each task, further automating the learning pipeline. Moreover, by properly formalizing the reward functions in shaping and terminal terms, we avoid the need for reward reflection and multiple stages of training in RL. This results in a streamlined, one-shot process translating the user’s text descriptions into deployable skills.